Retroactive Bounding Box
Category Refinement
This is part 2/2 of a series on postprocessing tricks I used to generate a large custom synthetic dataset on a shoestring budget. Read part 1 here.
The Concrete Problem
![]()
Classifying objects at a distance is difficult, but this ability is often critically important in machine vision systems. There are several ways to improve classification acuity (my own term for “accuracy at a distance”). You could add telephoto-lens cameras to your device, or pay people to produce more ground truth labeled data. These options require significant engineering/financial commitment. Instead, I created a relatively simple way of generating high-quality synthetic datasets called retrolabeling. After re-training my object detector on a retrolabeled dataset, the classification acuity of my object detection model improved significantly.
The Conceptual Solution
The solution, which I call retrolabeling, takes advantage of the obvious fact that classification is much easier for close/large objects. Retrolabeling keeps a record of the predicted categorization for a given object through its lifetime with the help of a multi-object tracking algorithm. Then, it determines the most likely category for that object through a voting system weighted for large detections. Finally, it overwrites the previous detections' categorizations with the newly elected category.
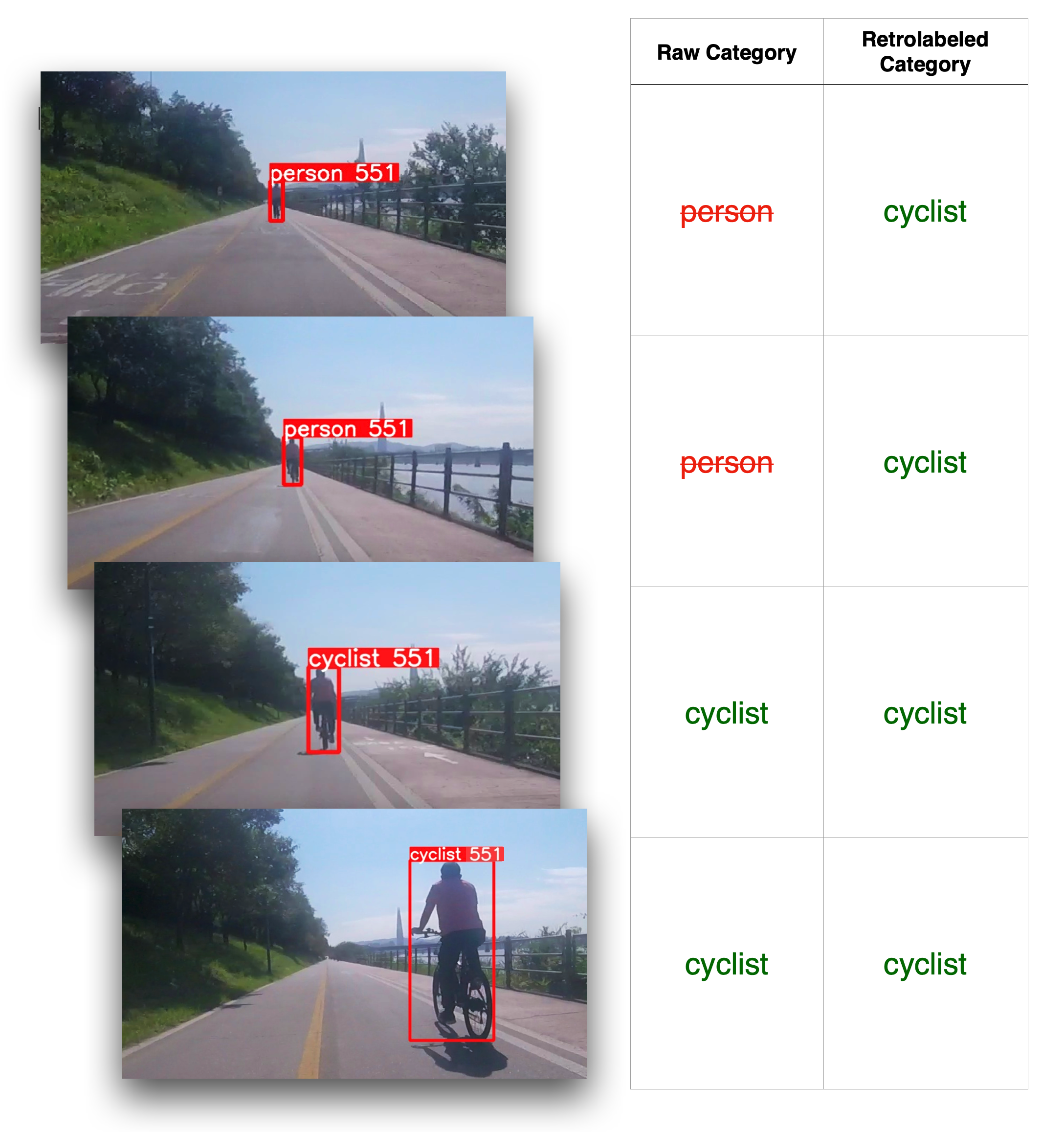
Note that retrolabeling is most effective for video datasets where most objects tend to approach or retreat from the camera, such as in self driving or mobility applications.
The Implementation
Part 1: Object detection & Tracking
autolabel.py uses
- YOLO v5, but any object detection model will do.
- IOU Tracker, but again, any object tracker will do, as long as you are careful (discussion will follow).
Pseudocode for the inference loop.
model = YOLOv5Model()
iou_tracker = IOUTracker()
for frame in video:
input_frame = preprocess(frame)
detections = model(input_frame)
fused_detections = fuse_bboxes(detections)
tracked_detections = iou_tracker(fused_detections)
if len(tracked_detections) > 0:
write_file(tracked_detections)
- What does
fuse_bboxes()do? See Robust Bounding Box Fusion with Combinatorial Optimization to find out.
The modified YOLOv5 inference loop outputs one text file per image, one line per object, structured as follows:
<frame_number>, <track_id>, <bbox_left>, <bbox_top>, <bbox_width>, <bbox_height>, <confidence>, <class_id>
Part 2: Retrolabeling
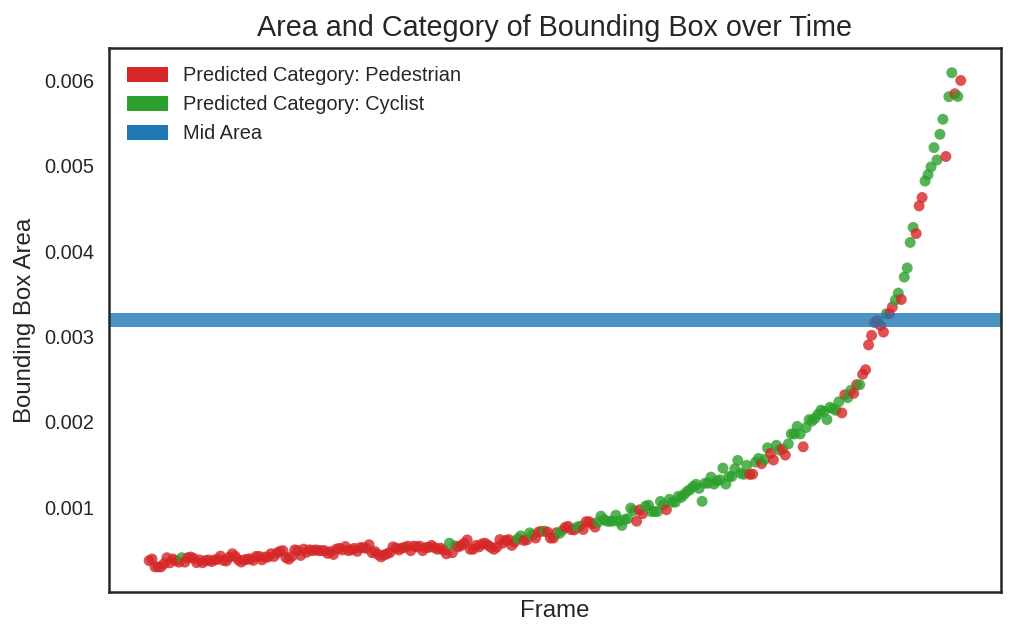
to cyclist for 'object 551' as it gets closer.
In this diagram, an object that looked like a pedestrian at first turns out to be a cyclist. The voted category is the most common category above the blue line. Retrolabeling overwrites the categories for of these data points on the disk. This calculation is repeated for every single tracked object.
Since retrolabel.py only needs to read/write the text annotation files, it is quite fast, taking only a handful of seconds to process the detections corresponding to 40,000 images.
Experimental Results
I plan on benchmarking the impact of retrolabeling on multi-object detection performance, but this will take some time. Results coming soon.
Future Work
- There is at least an order of mangitude of speed to be gained during the autolabeling step with TensorRT & batch inference.
- A more sophisticated object tracker could replace IOU Tracker. However, one should be careful to use raw bounding boxes, not the predicted bboxes that the tracker outputs.
Epilogue
Retrolabeling is free and fast. If you’ve got a computer vision model that would benefit from higher categorization acuity, try retrolabeling today as part of hydoai/synthlabel.
Posted on